原创 油醋 品玩


作者|油醋
邮箱|zhuzheng@pingwest.com
这个片段的出处是哪儿?这种问题就像是手挠不到后背的痒。
大部分时候,遇到这样的情况,你可以做的就是把视频里的金句摘出来,用文字去网上问。不然,就截图去搜索引擎或者视频平台上搜。两者的前提都是把你看到的视频片段再降些维度,抽象成更简单的东西。但如果碰上冷门的视频或者视频中的语言你无法听懂,难题就来了。
所以,能不能直接用视频搜视频呢?
文字搜万物
目前来看,人们讨论的“视频搜索”更多依托于传统的输入文字完成搜索的模式。
抖音方面此前表示,抖音搜索在技术上会重点关注多模态信号补充,基于此,有两项技术在辅佐着这种传统意义上的视频搜索的精确性——OCR(光学文字识别)和ASR(语音识别)。
OCR全称Optical Character Recognition,直白点说就是能把图像中的(换到视频就是其中某几桢)出现的文字识别出来。路况监控读取车牌,拍照上传银行卡面读取卡号都是这项技术的日常应用。目前常用的OCR库有Google的开源项目tesseract以及微软提供API的Azure。在国内机器学习技术顶尖的百度也在去年开源了自己的OCR库PaddleOCR。
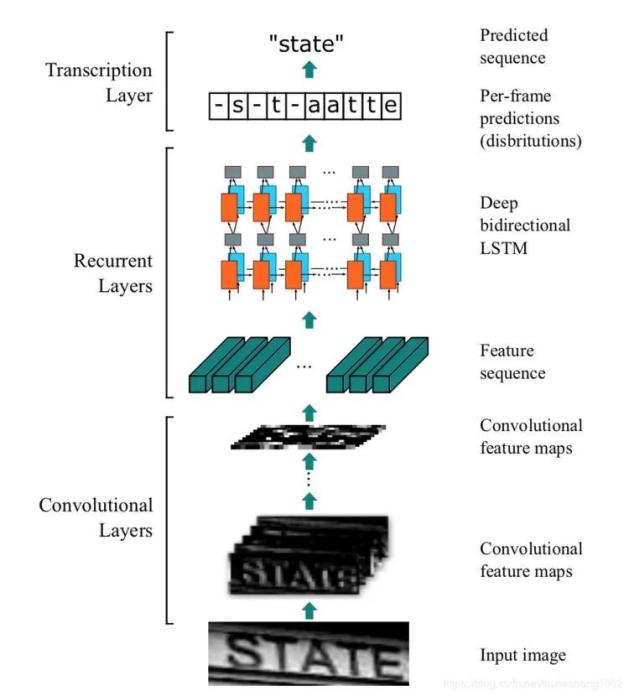
ASR(Automatic Speech Recognition)则与OCR对应,可以用于将视频内容中的语音内容提取出来,成为被检索的标记。SIRI与微信语音转文字都是这项技术的应用。
但这两项技术实际上只能完成最浅的视频搜索情景,它们的基础是“我知道我要看的东西叫什么”,并且最好视频本身已经预制了文本标签。
如果只是依靠OCR与ASR技术,同样的一只老虎在理论上需要脖子上挂一块牌子写着“老虎”才能被搜索出来。并且很可能脖子上写的是“我不是老虎”的那些,也会出现在搜索结果里。
但比如我想要搜索电影《机器人总动员》里的“瓦力”,又不知道电影和机器人的名字,我可能就只能搜“长得一个垃圾桶的机器人”,然后期待茫茫人海中有人给“瓦力”标记“垃圾桶”,之后托付给伟大的机器学习。
而它仍然很有可能把天行者卢克身边的R2-D2推给我。

其实谷歌在2017年就已经对视频搜索技术做了推进。
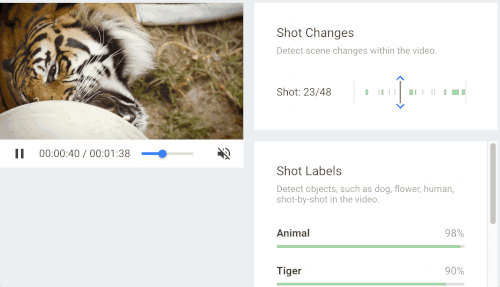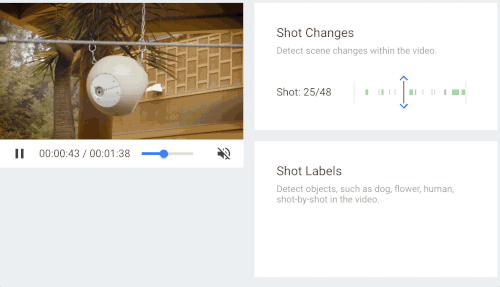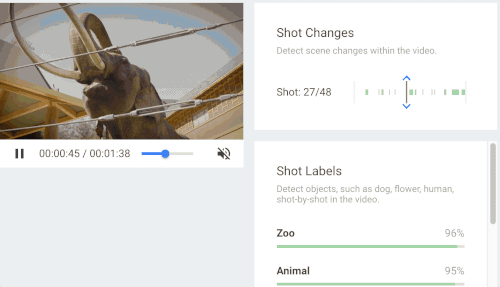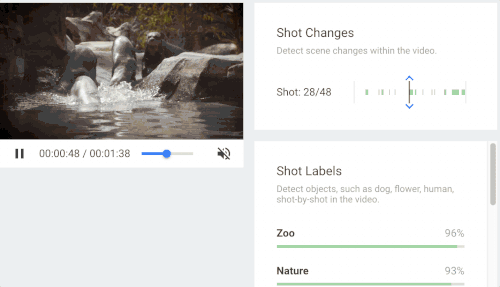
当时的Google Cloud Next云端大会上,谷歌公开了一个基于深度机器学习的视频技术应用Cloud Video Intelligence API。当时的谷歌副总裁李飞飞现场演示了谷歌在深度机器学习的基础上,已经可以做到在视频中精确定位某个客体出现的时间。
这项技术在视频搜索上的意义是可以将纯粹的图像信息进行归类,让它们可以被检索。比如搜索“老虎”,在视频资料库中所有与老虎相关的视频都会被标记并且按相关程度列出。这项技术解决了搜索过程中只能将一切转化为文字再进行机器学习或者匹配的一般逻辑,李飞飞也视其为“黑暗中为数字世界点燃一盏烛光”。
同样是2017年,阿里文娱和达摩院在视频搜索上也进行了关于语言、语音等多模态视频搜索的实践。其中一个技术方案是利用人脸识别的技术,识别出视频中出现的人物如黄子韬、易烊千玺,“再通过 OCR/ASR 技术,识别各视频中的对话内容并转化成文本,然后基于文本去做结构化理解”。
2019年事情又往前推进了一步。谷歌开始尝试在涉及Youtube的英文视频搜索中直接显示视频中段的相关内容。Engadget的报道称,这意味着如果你要搜索某支曲子,搜索结果会显示某场包含这首曲子的音乐会,并且进度条直接拉到这首曲子的位置。
但这项技术目前仍然依赖上传者在视频中手动添加时间标记。并且这样的技术本质上仍然是将其他模态形式的信息转译成文本,并没有动摇传统搜索模式以文字输入为基础的基本形态。
丢掉文字,视频搜视频?
回到开头的问题,我如果手头上只有一个视频片段,要怎么搜索呢?依赖文字输入的搜索功能并不能完成这个任务。这时候只能以视频搜索视频。
现实的情况是,把一整个视频作为搜索依据还有点难,不过可以将视频定格在某一桢,而这其实就是现在已经随处可见的图片搜索。
图片搜索最早要追溯到28年前。
1992年,日本学者T.Kato在一篇论文里首次提出了基于内容的图像检索(CBIR)概念。CBIR技术通俗来说是一种匹配技术。在输入一个样本图片文件时,将图像中的色彩(颜色直方图、颜色一致性矢量等参数)、形状(面积、曲率等)和纹理等信息进行特征提取,进行编码,然后将图像编码放到信息库中去寻找相似图像。
基于此,IBM Aimaden研究中心开发了第一个商用的CBIR系统QBIC。谷歌也在2001年推出了图片搜索服务。而在精确度方面的发展,则托付给了深度学习技术。

抖音在2019年曾推出过抖音识图的功能,通过人脸识别技术,用户搜索到一则短视频中出现人物的所有抖音视频。但抖音推出识图功能的主要动力还是其在电商方面的潜力。利用这项技术,抖音博主自己带货的衣服可以直接被识别出来链接到商品,节约了中间更多的跳转步骤。
而在2020年,阿里巴巴淘系技术部与北京大学前沿计算研究中心CVDA实验室、英国爱丁堡大学等合作,正式开源业界首个大规模的多模态直播服饰检索数据集(Watch and Buy)。借助PixelAI 商品识别算法,商品的图片识别已经可以被应用在直播环境中。

但图片搜索所面临的风险也高于文字,美国媒体DIGITAL TREND在抖音识图上线后不久就表示出对于私人视频信息安全的质疑,而这个实验性的功能目前也已经从抖音的侧栏里下线。
不过,这些技术已经基本能满足大多数的视频搜索需求。可以看出,目前的搜索逻辑都是从低维到高维(文字搜图片,图片搜视频),在各种媒介形式中,视频是复杂程度最高的。另一方面,视频形式对于用户来说完成度太高,把所有东西都揉在一起。如果能通过搜索功能把与视频相关的文字和图片搜索结果拆解出来,这可能才是视频媒介越来越成为主流之后,我们对视频搜索的期待。

但鉴于在视频在保存和格式统一上的高门槛,其作为搜索输入端的价值不高。并且由于版权限制,视频素材未来会越来越被各个平台圈地保护,这又导致视频搜索先天性地只能变成某种形式的站内搜索,而失去了作为一个开放搜索平台的内容宽度。
所以无论怎么看,用视频搜索内容可能仍然是个遥远的事情。

· 文章版权归品玩所有,未经授权不得转载。
原标题:《我们是否需要视频搜索?》