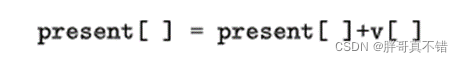说明:这是一个机器学习实战项目(附带数据+代码+文档+代码讲解),如需数据+代码+文档+代码讲解可以直接到文章最后获取。
1.项目背景
粒子群优化算法(Particle Swarm optimization,PSO)又翻译为粒子群算法、微粒群算法、或微粒群优化算法。是通过模拟鸟群觅食行为而发展起来的一种基于群体协作的随机搜索算法。通常认为它是群集智能 (Swarm intelligence, SI) 的一种。它可以被纳入多主体优化系统(Multiagent Optimization System, MAOS)。粒子群优化算法是由Eberhart博士和kennedy博士发明。
PSO模拟鸟群的捕食行为。一群鸟在随机搜索食物,在这个区域里只有一块食物。所有的鸟都不知道食物在那里。但是他们知道当前的位置离食物还有多远。那么找到食物的最优策略是什么呢。最简单有效的就是搜寻离食物最近的鸟的周围区域。
PSO从这种模型中得到启示并用于解决优化问题。PSO中,每个优化问题的解都是搜索空间中的一只鸟。我们称之为“粒子”。所有的粒子都有一个由被优化的函数决定的适应值(fitnessvalue),每个粒子还有一个速度决定他们飞翔的方向和距离。然后粒子们就追随当前的最优粒子在解空间中搜索。
PSO初始化为一群随机粒子(随机解),然后通过迭代找到最优解,在每一次迭代中,粒子通过跟踪两个“极值”来更新自己。第一个就是粒子本身所找到的最优解,这个解叫做个体极值pBest,另一个极值是整个种群找到的最优解,这个极值是全局极值gBest。另外也可以不用整个种群而只是用其中一部分最优粒子的邻居,那么在所有邻居中的极值就是局部极值。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
数据详情如下(部分展示):
3.数据预处理
真实数据中可能包含了大量的缺失值和噪音数据或人工录入错误导致有异常点存在,非常不利于算法模型的训练。数据清洗的结果是对各种脏数据进行对应方式的处理,得到标准的、干净的、连续的数据,提供给数据统计、数据挖掘等使用。数据预处理通常包含数据清洗、归约、聚合、转换、抽样等方式,数据预处理质量决定了后续数据分析挖掘及建模工作的精度和泛化价值。以下简要介绍数据预处理工作中主要的预处理方法:
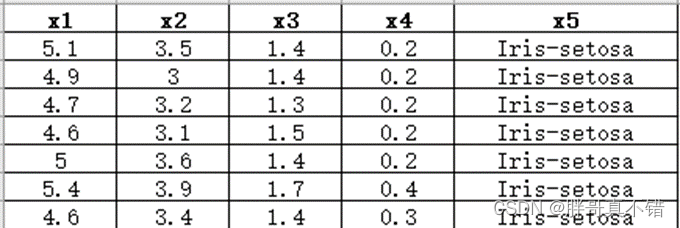
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:
关键代码:
3.2查看数据集摘要
使用Pandas工具的info()方法查看数据集的摘要信息:
从上图可以看到,总共有150条数据,5个数据项,所有数据中没有缺失值。
关键代码:
3.3数据描述性统计分析
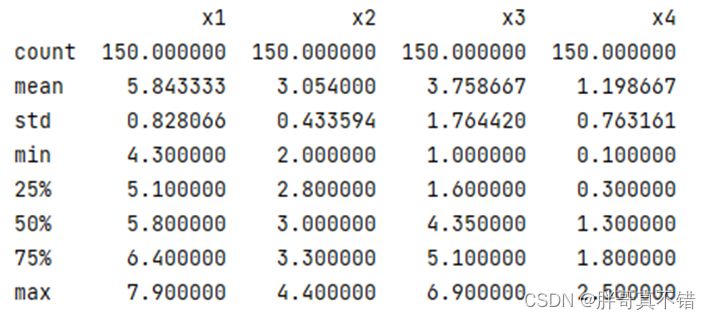
使用Pandas工具的describe()方法查看数据描述性统计分析信息:
通过上图可以看到,总数据量150条,每个数据项的平均值、标准差、最大值、最小值以及分位数值。其中x1平均值为5.84、标准差为0.83、最小值为4.30、最大值为7.90。
关键代码:
4.探索性数据分析
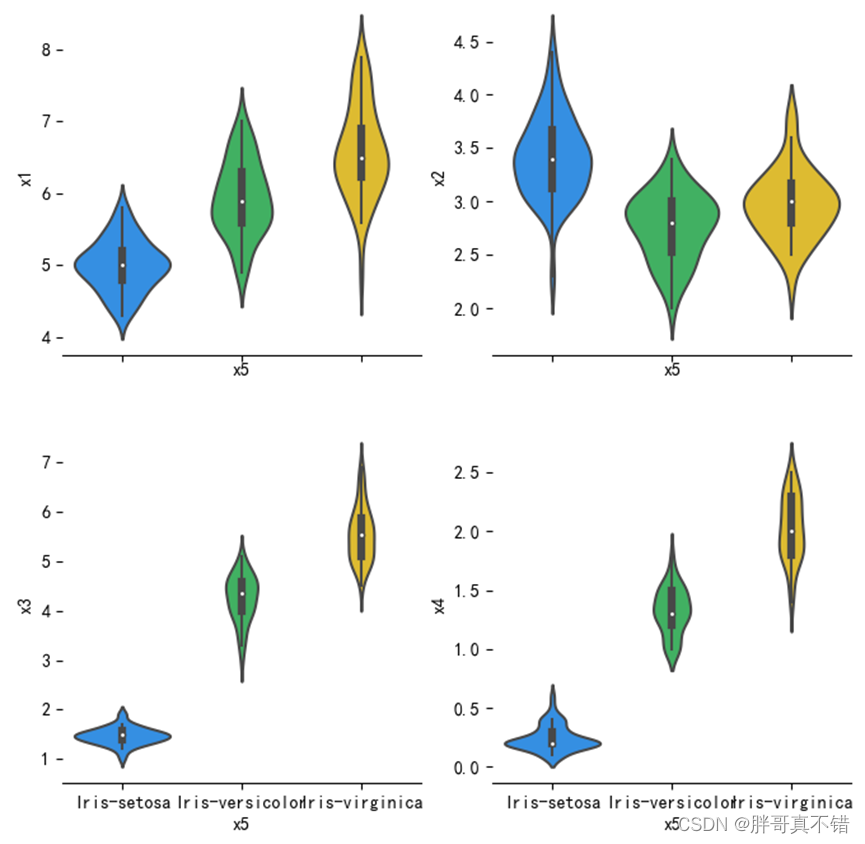
4.1绘制特征与标签的小提琴图
用seaborn工具的violinplot()方法进行绘图,图形化展示如下:
从上面图中可以看到,品种与每个特征之间的数据分布,例如:花萼长度特征,可以看到中位数、最大值、最小值等,品种为山鸢尾的中位数在5左右、品种为杂色鸢尾的中位数为5.5左右、品种为维吉尼亚鸢尾的中位数为6.3左右,以及针对每个品种 花萼长度数据的一个分布情况,其它特征的分析一样,就不一个一个分析。
4.2绘制特征与标签的点图
用seaborn工具的pointplot ()方法进行绘图,图形化展示如下:
从上面图中可以看到,品种与每个特征之间的数据分布,例如:花萼长度特征,可以看到平均值,品种为山鸢尾的平均值在5左右、品种为杂色鸢尾的平均值为5.8左右、品种为维吉尼亚鸢尾的平均值为6.5左右,就不一个一个分析。
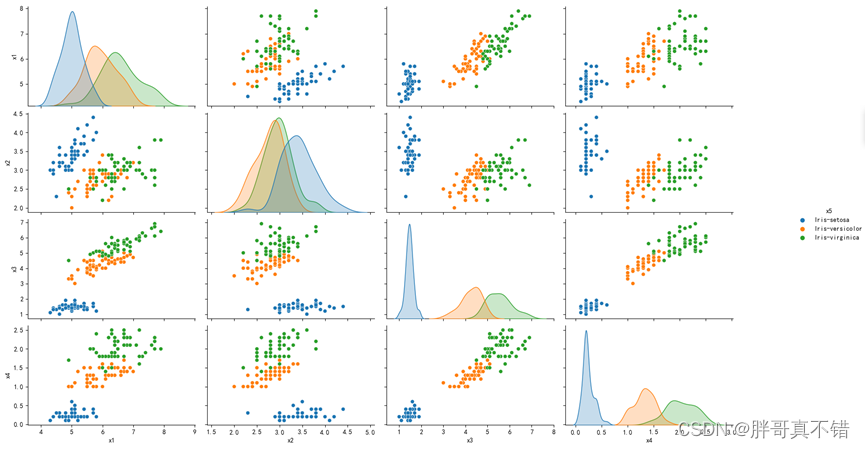
4.3生成各特征之间关系的矩阵图
用seaborn工具的pairplot ()方法进行绘图,图形化展示如下:
从上图可以看到,花萼长度越小、花瓣宽度越窄 品种越偏向于山鸢尾;其它特征的分析以此类推。
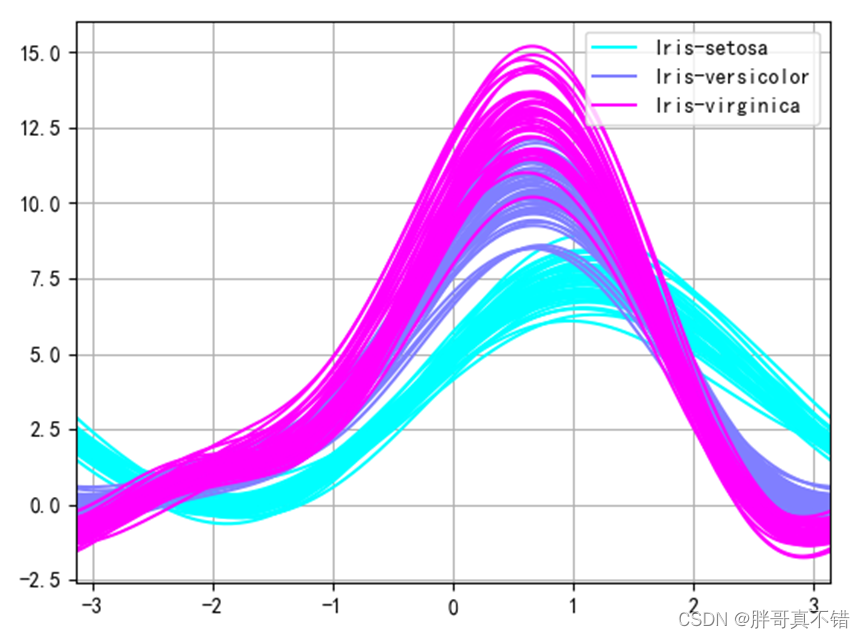
4.4多维数据线性可视化
用seaborn工具的andrews_curves()方法进行绘图,图形化展示如下:
通过上图可以清晰地看到每一个品种的鸢尾花数据的一个趋势,方便看到是否有异常的数据;本次可以看到无异常的数据。
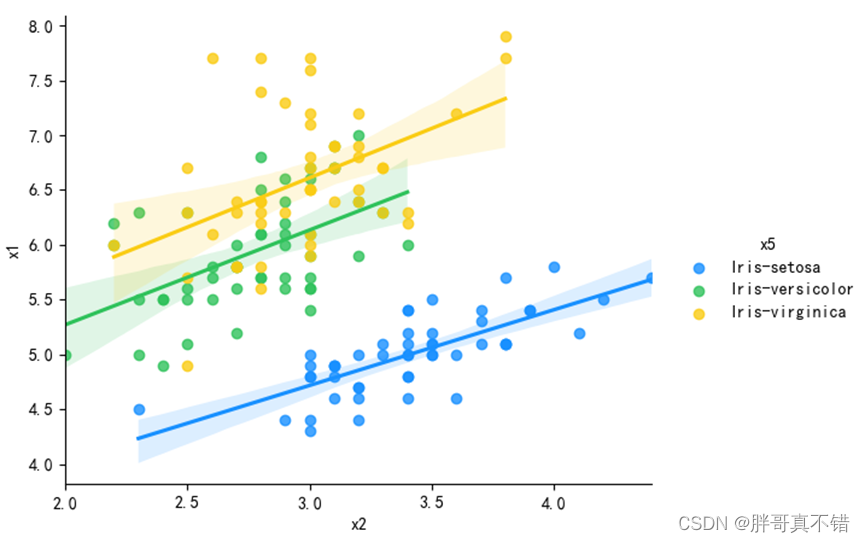
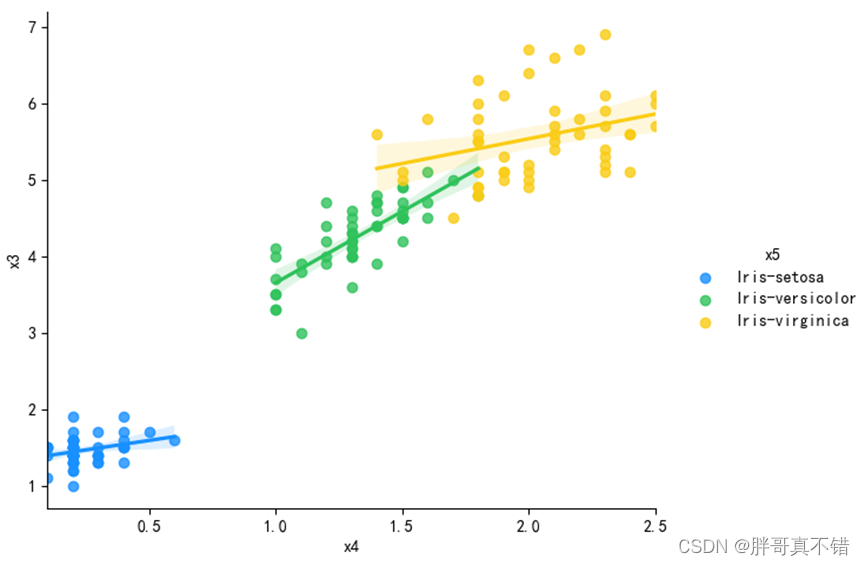
4.5基于花萼和花瓣做线性回归可视化
用seaborn工具的lmplot()方法进行绘图,图形化展示如下:
通过上图可以看到三种品种鸢尾花的花萼宽度与花萼长度的线性数据分布。
通过上图可以看到三种品种鸢尾花的花瓣宽度与花瓣长度的线性数据分布。
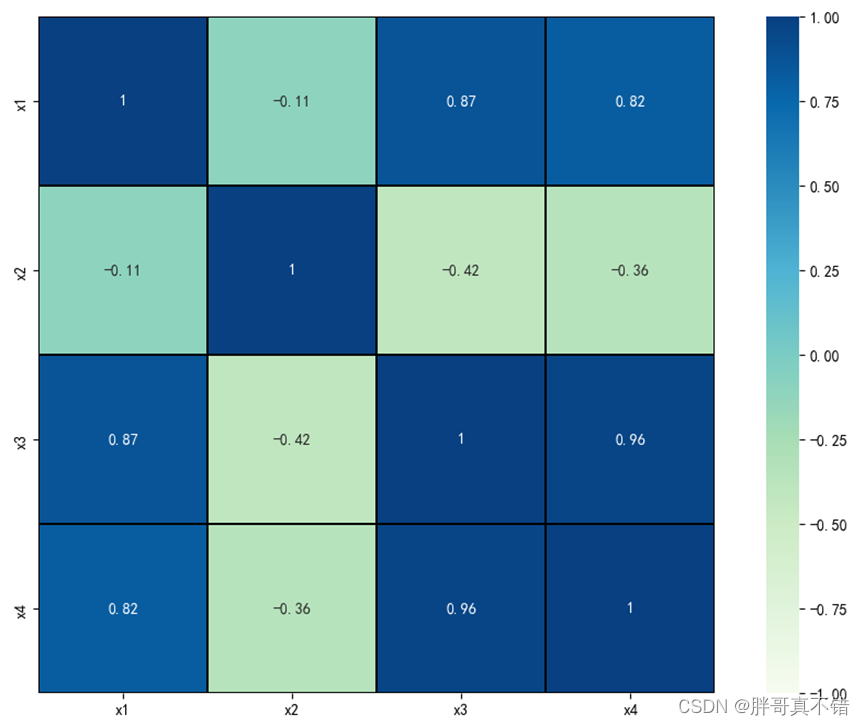
4.6相关性分析
用Pandas工具的corr()方法 matplotlib seaborn进行相关性分析,结果如下:
通过上图可以看到,数据项之间正值是正相关/负值是负相关,数值越大 相关性越强;花萼长度与花萼宽度不相关、花萼长度与花瓣长度、花瓣宽度相关性比较大。
5.特征工程
5.1 建立特征数据和标签数据
x5为标签数据,除x5之外的为特征数据。关键代码如下:
6.用PSO构建KMeans聚类模型
主要使用PSO粒子群优化算法和KMeans聚类算法,用于目标聚类。
PSO粒子群优化算法介绍:
v[] 是粒子的速度,present[] 是当前粒子的位置。pbest[] 和 gbest[] 如前定义。rand() 是介于(0,1)之间的随机数。c1,c2是学习因子。通常c1=c2=2。
PSO中并没有许多需要调节的参数,下面列出了这些参数以及经验设置:
- 粒子数: 一般取 20–40. 其实对于大部分的问题10个粒子已经足够可以取得好的结果, 不过对于比较难的问题或者特定类别的问题, 粒子数可以取到100 或 200
- 粒子的长度: 这是由优化问题决定, 就是问题解的长度
- 粒子的范围: 由优化问题决定,每一维可是设定不同的范围
- Vmax: 最大速度,决定粒子在一个循环中最大的移动距离,通常设定为粒子的范围宽度,例如上面的例子里,粒子 (x1, x2, x3) x1 属于 [-10, 10], 那么 Vmax 的大小就是 20
- 学习因子: c1 和 c2 通常等于 2. 不过在文献中也有其他的取值. 但是一般 c1 等于 c2 并且范围在0和4之间
- 中止条件: 最大循环数以及最小错误要求. 例如, 在上面的神经网络训练例子中, 最小错误可以设定为1个错误聚类, 最大循环设定为2000, 这个中止条件由具体的问题确定.
- 全局PSO和局部PSO: 我们介绍了两种版本的粒子群优化算法: 全局版和局部版. 前者速度快不过有时会陷入局部最优. 后者收敛速度慢一点不过很难陷入局部最优. 在实际应用中, 可以先用全局PSO找到大致的结果,再用局部PSO进行搜索.
- 另外的一个参数是惯性权重。
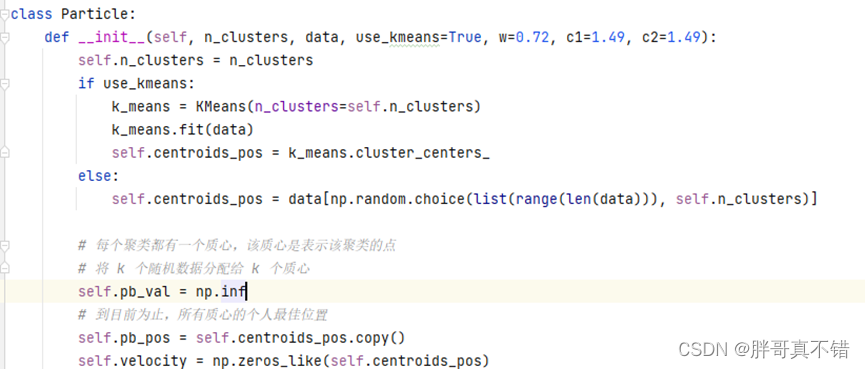
6.1建模
关键代码如下:
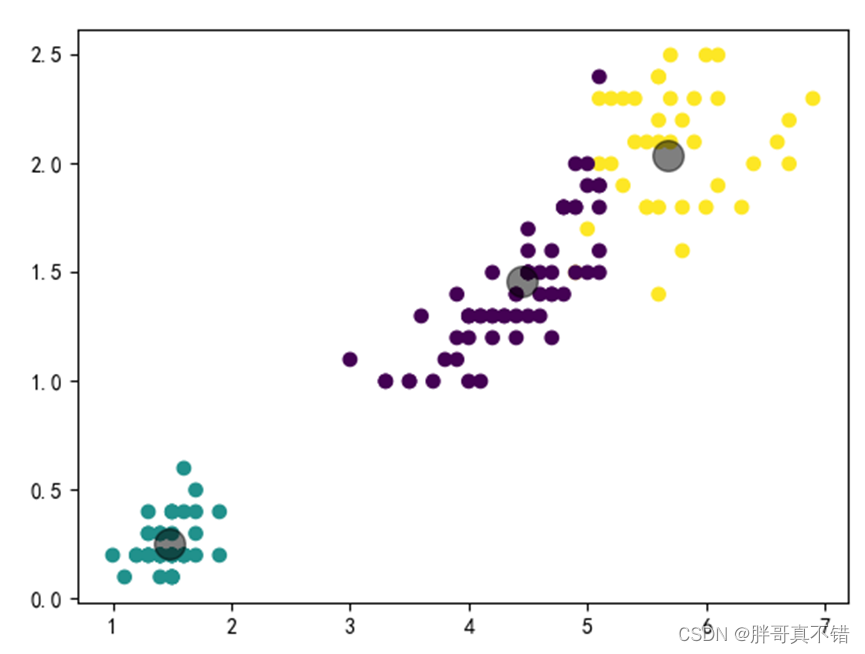
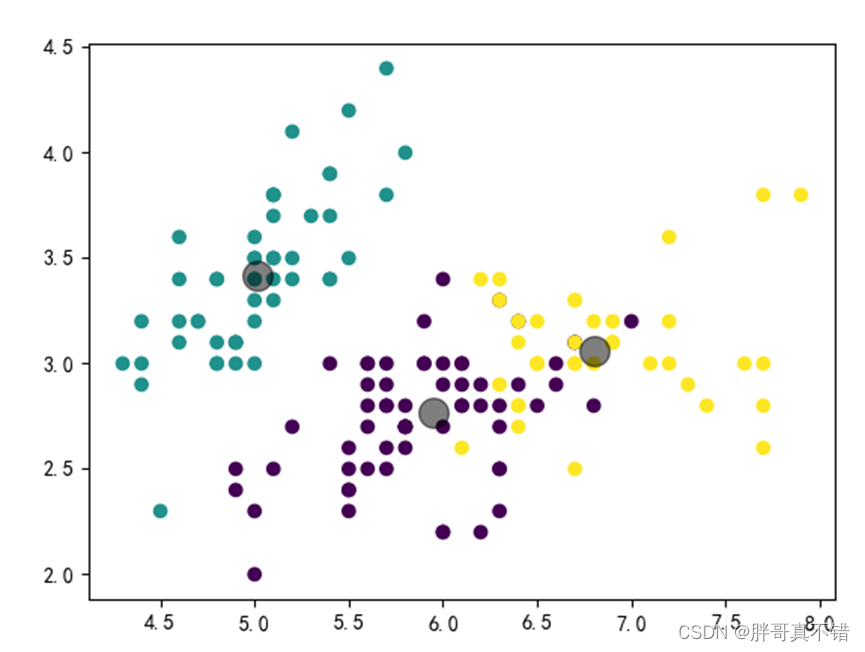
6.2聚类结果
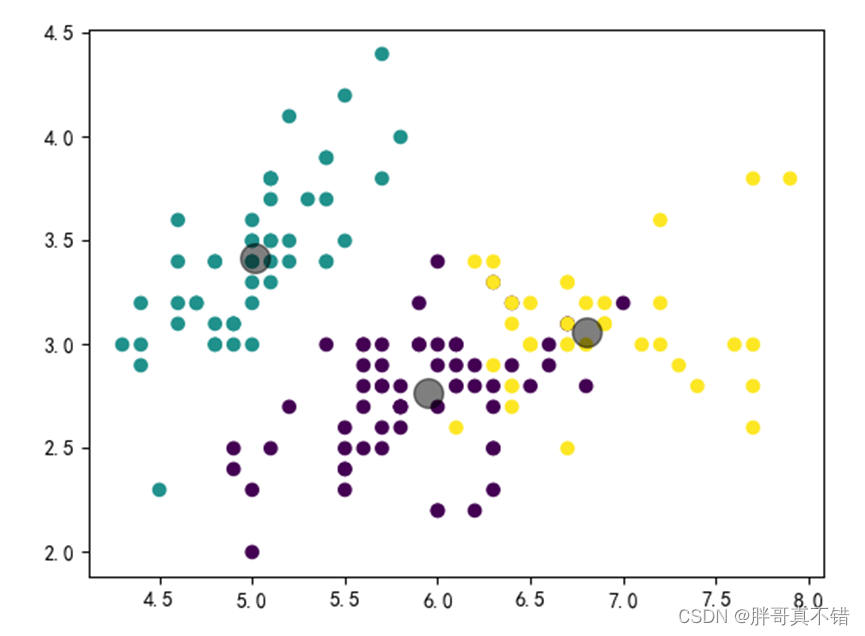
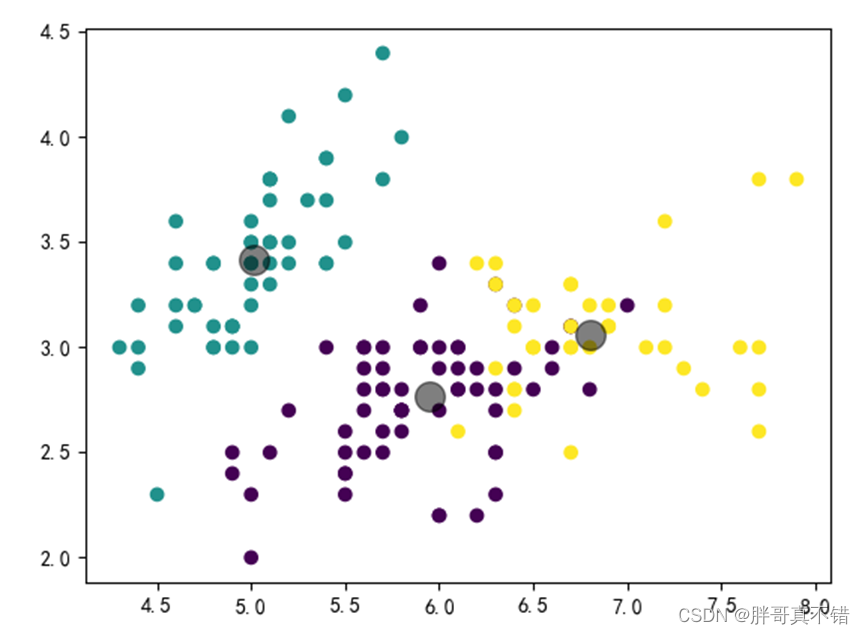
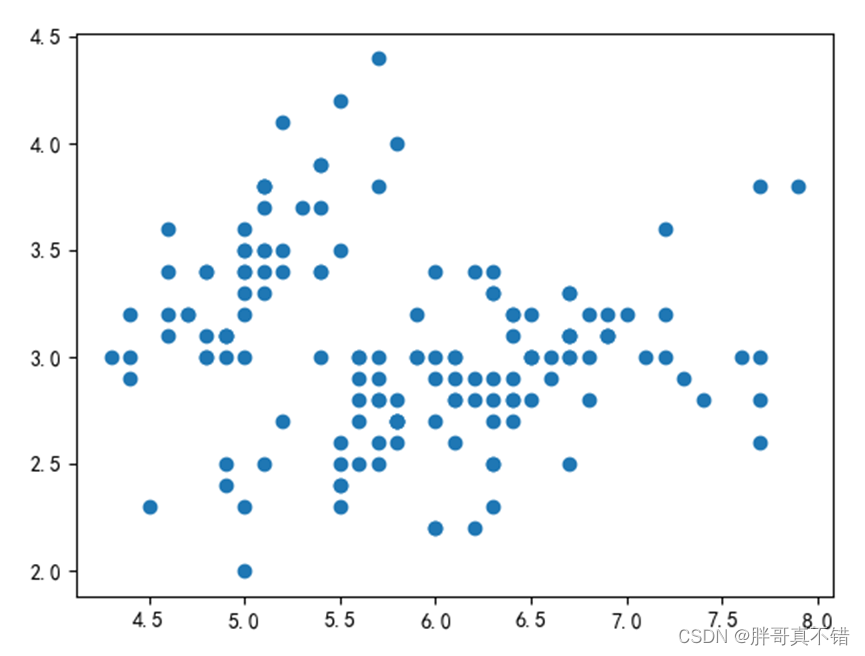
没有簇,迭代次数为0的聚类结果为:
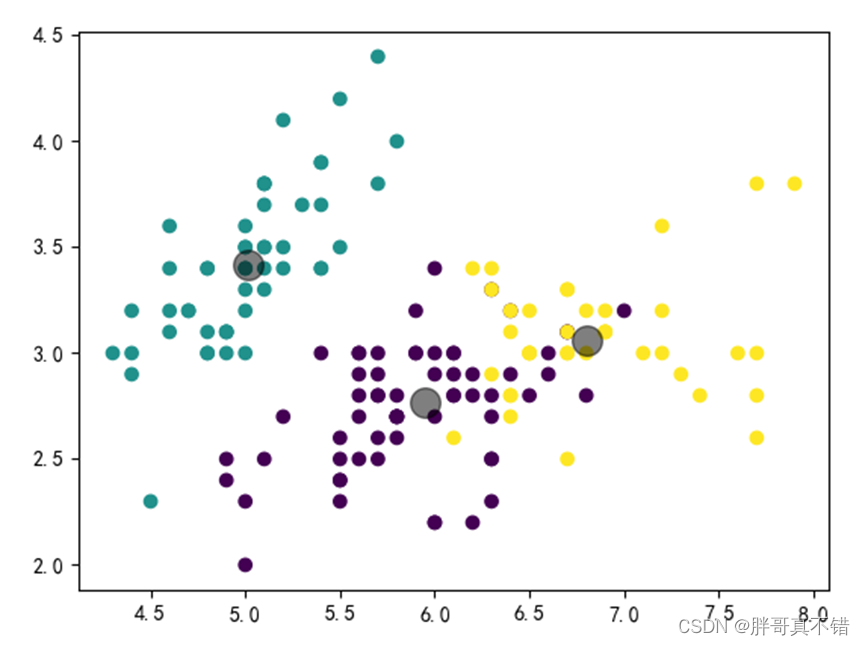
迭代200次,聚类结果为:
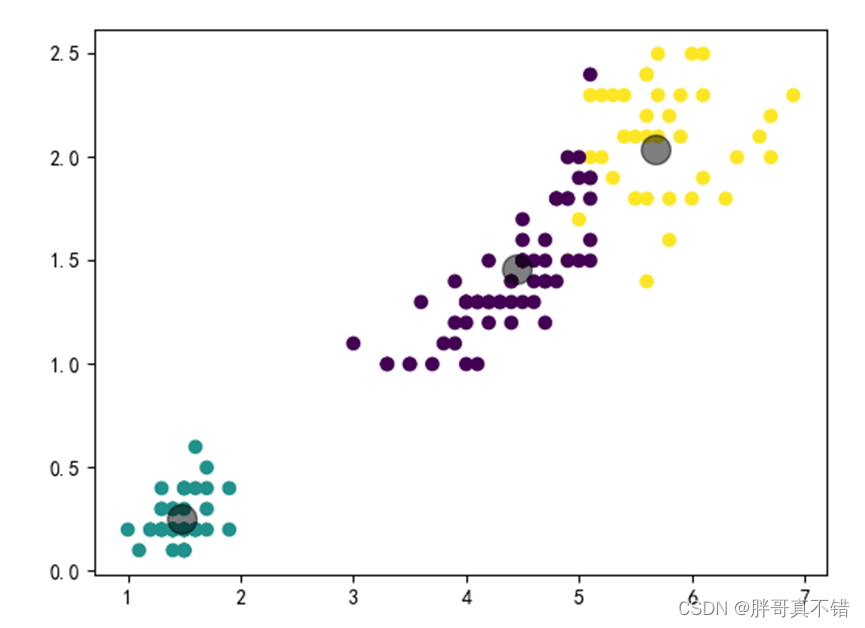
迭代400次,聚类结果为:
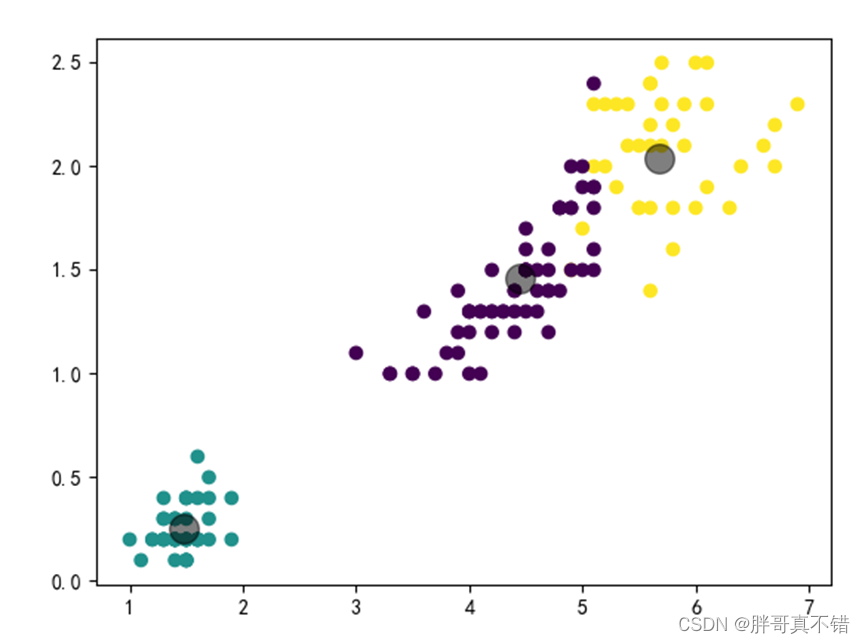
迭代600次,聚类结果为:
迭代800次,聚类结果为:
7.模型评估
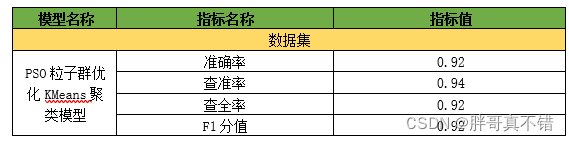
7.1评估指标及结果
评估指标主要包括准确率、查准率、查全率、F1分值等等。
从上表可以看出,PSO粒子群优化KMeans聚类模型准确率为92% F1分值为92%,模型相当不错。
关键代码如下:
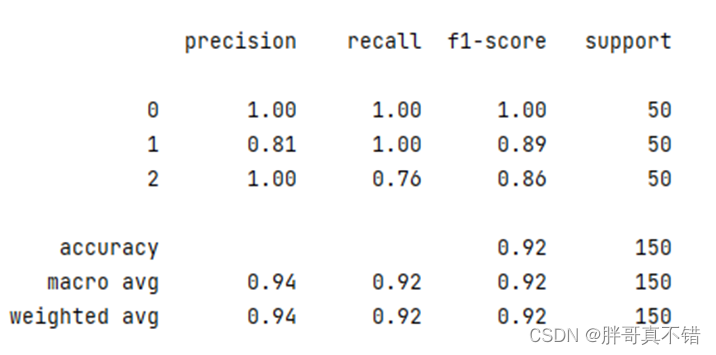
7.2聚类报告
PSO粒子群优化KMeans聚类模型聚类报告:
从上图可以看到,聚类类型为0的F1分值为1.00;聚类类型为1的F1分值为0.89;聚类类型为2的F1分值为0.86;整个模型的准确率为92%.
8.结论与展望
综上所述,本文采用了PSO粒子群算法优化KMeans聚类模型,最终证明了我们提出的模型效果良好。准确率达到了92%,可用于日常生活中进行建模预测,以提高价值。
新闻中心