目录
")
3.2 报表系统架构的改进
3.2.1 原有报告系统的问题:
3.2.2 改进方案:
3.2.2 同步模块架构设计
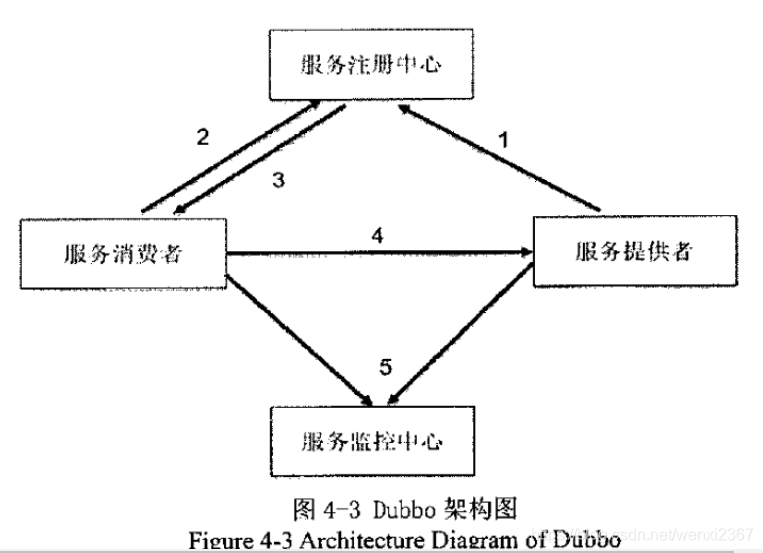
4.3 分布式服务架构
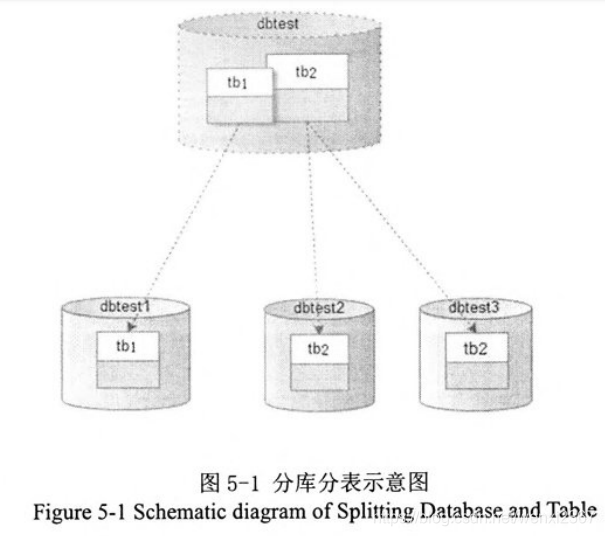
5.2.1关系型数据库现状分析——分库分表
5.2.3 字表导入FDFS 模块的设计与实现
5.3.2 Hive 绑定模块的设计与实现
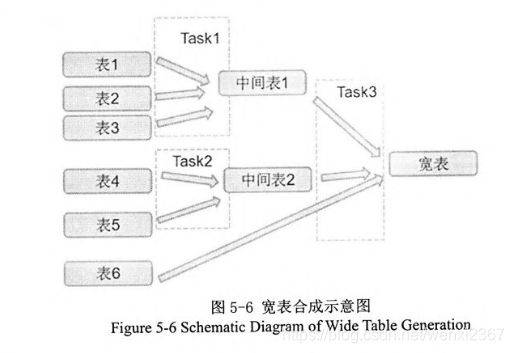
5.4 宽表合成模块
5.5 索引文件生成
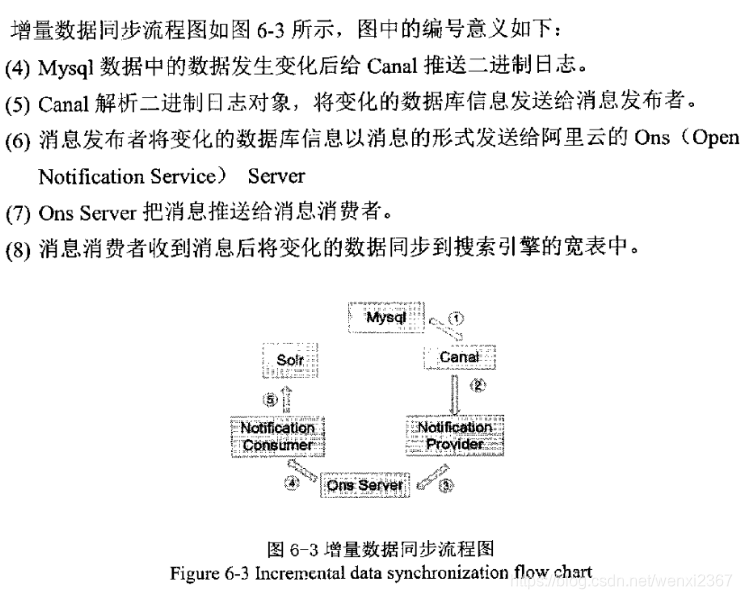
6.2.3 增量数据同步流程
https://www.doc88.com/p-2052553782070.html




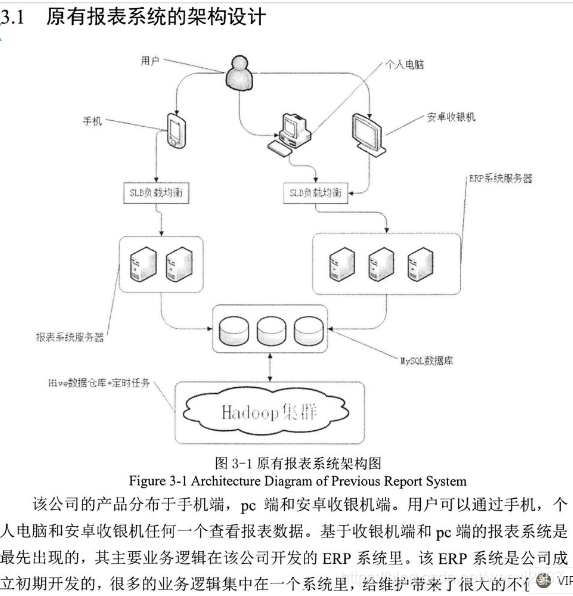
3.2.1 原有报告系统的问题:
- 不及时
- 业务逻辑冗余,难以维护
- 数据藏的虎的数据同步用脚本单线程导入,慢,时间长
3.2.2 改进方案:
1.原有架构缺乏实时性,是因为选择离线计算模式处理数据。垮裤跨表查询性能不足,不支持跨库跨表。
-
可选择分布式索引来提供复杂业务的实时数据查询。
-
同事保证是增量数据的实时同步,应当保证数据库的数据在发生变化后及时更新到分布式索引中去。
2.将报表的业务剥离出来,形成独立于其他系统的报表服务
3.原来的架构中数据的同步和计算是写在脚本文件中,直接分布在Hadoop的NameNode的节点上,工作效率不高。
应该充分利用HDFS(分布式文件系统(Hadoop Distributed File System))的高吞吐量的特性,缩短数据库同步至数据库同步中Hadoop集群的时间。
可以利用Java多线程技术动态地选择MySQL数据库进行数据库读取,充分利用系统资源。
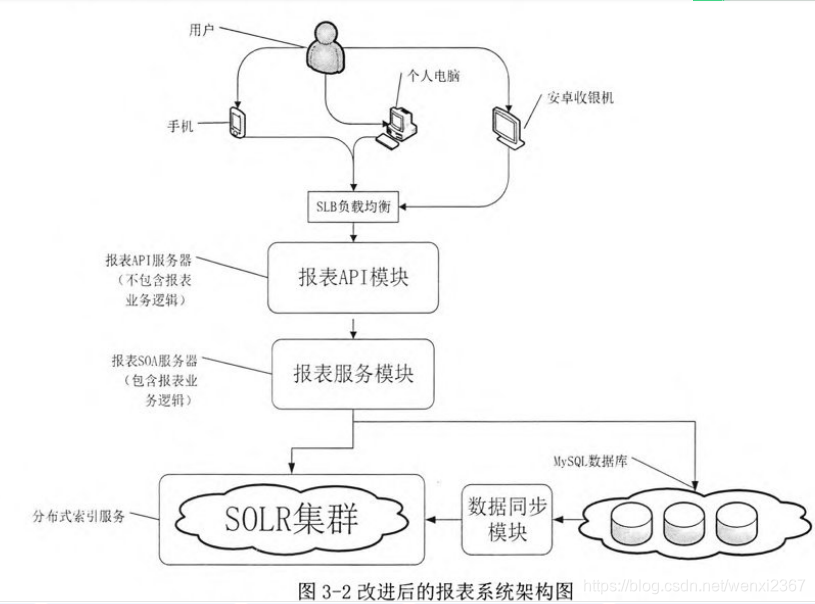
报表服务模块中额数据查询可以从分布式索引中刚查询,也可以冲MySQL数据库中查询。少数较为简单的数据查询是直接查询MySQL。例如只访问某一张表。
分布式检索引擎Solr的问世,为解决海量数据查询提供了另一种处理模式。Solr支持为数据库的记录建立索引。数据库记录抽象为文档,由多个字段组成,每个字段由一个单词组成,并使用倒排索引技术来创建索引。倒排索引是目前应用最广泛的索引模型。
在分布式索引中的数据在逻辑上是以宽表的形式存储的。
宽表的优点:
- 在海量数据的情况下,从分布式索引服务中查询数据速度极快。
- 避免了数据间表连接查询,一次性返回全部的有效字段。

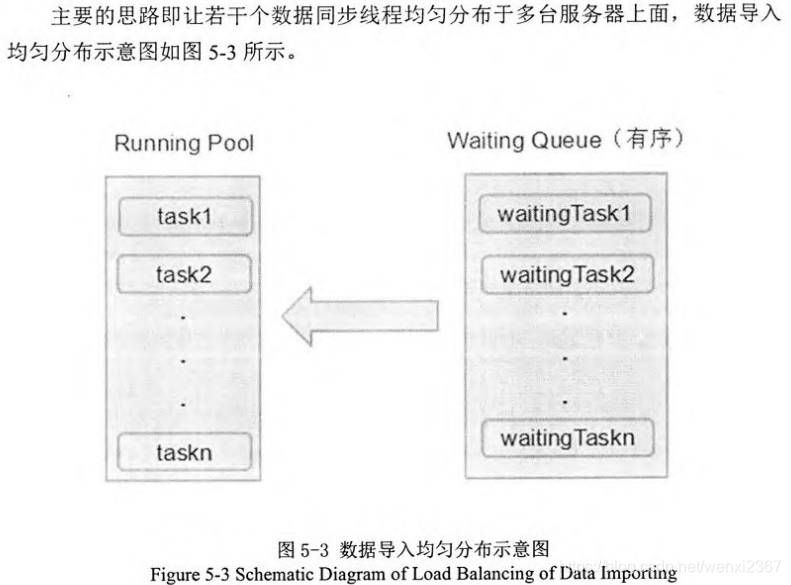
3.2.2 同步模块架构设计

5.2.1关系型数据库现状分析——分库分表
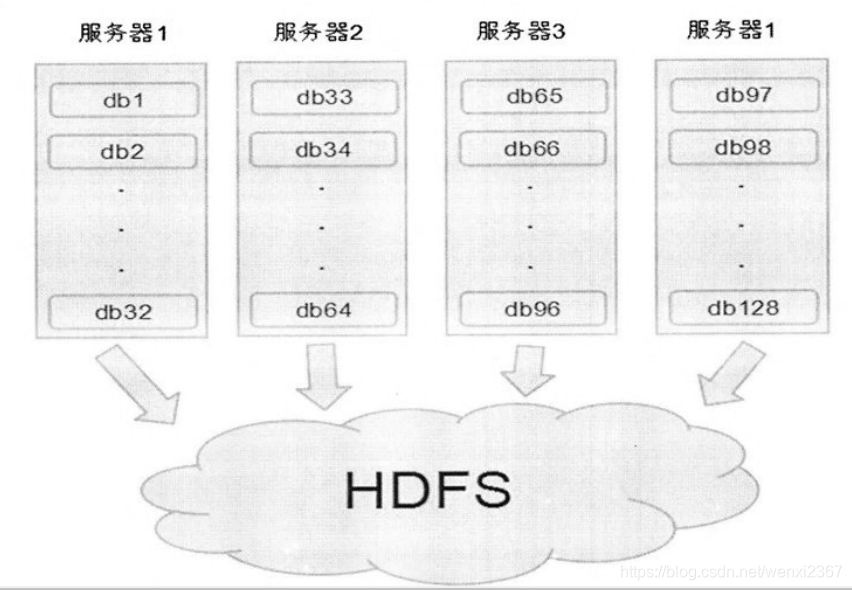
5.2.3 字表导入FDFS 模块的设计与实现




5.3.2 Hive 绑定模块的设计与实现




 、
、

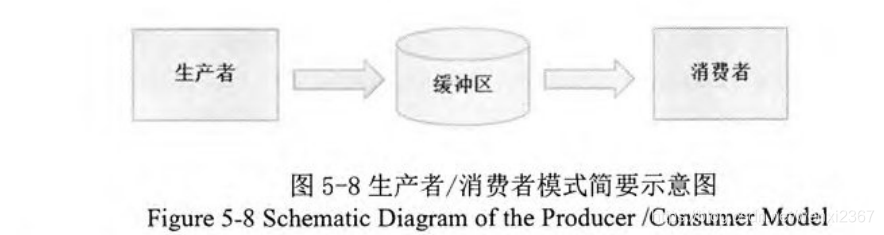
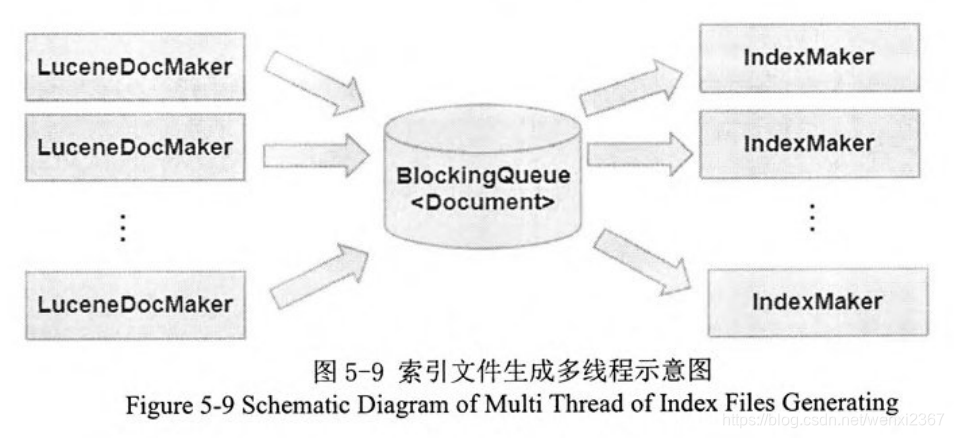
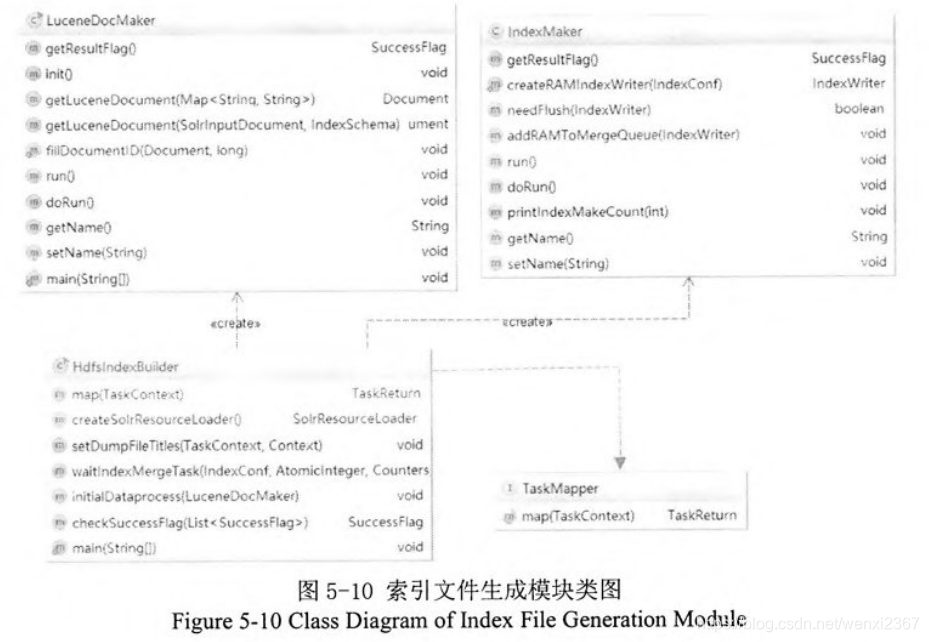
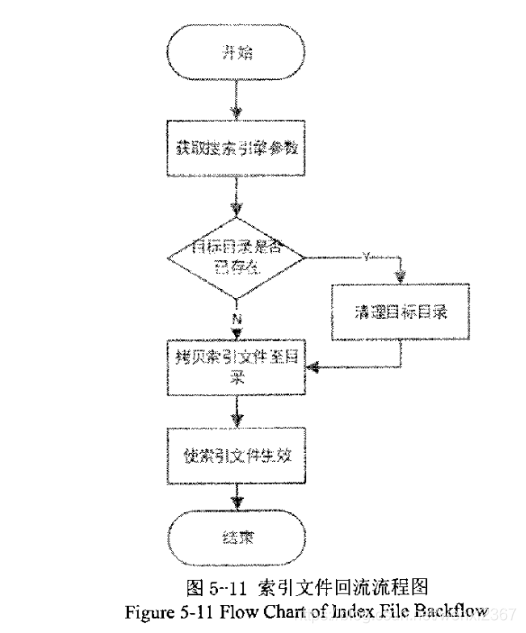
索引文件回流:
索引文件拷贝到搜索引擎服务器
6.2.3 增量数据同步流程